SmartBin
A full-stack AI waste classifier — upload a photo, eleven deep learning models decide which bin it goes in.
- Type
- Web
- Role
- Solo
- Status
- Active
- Tech
- FastAPI PyTorch Next.js TypeScript Docker AWS
- Started
- Oct 2024
Overview
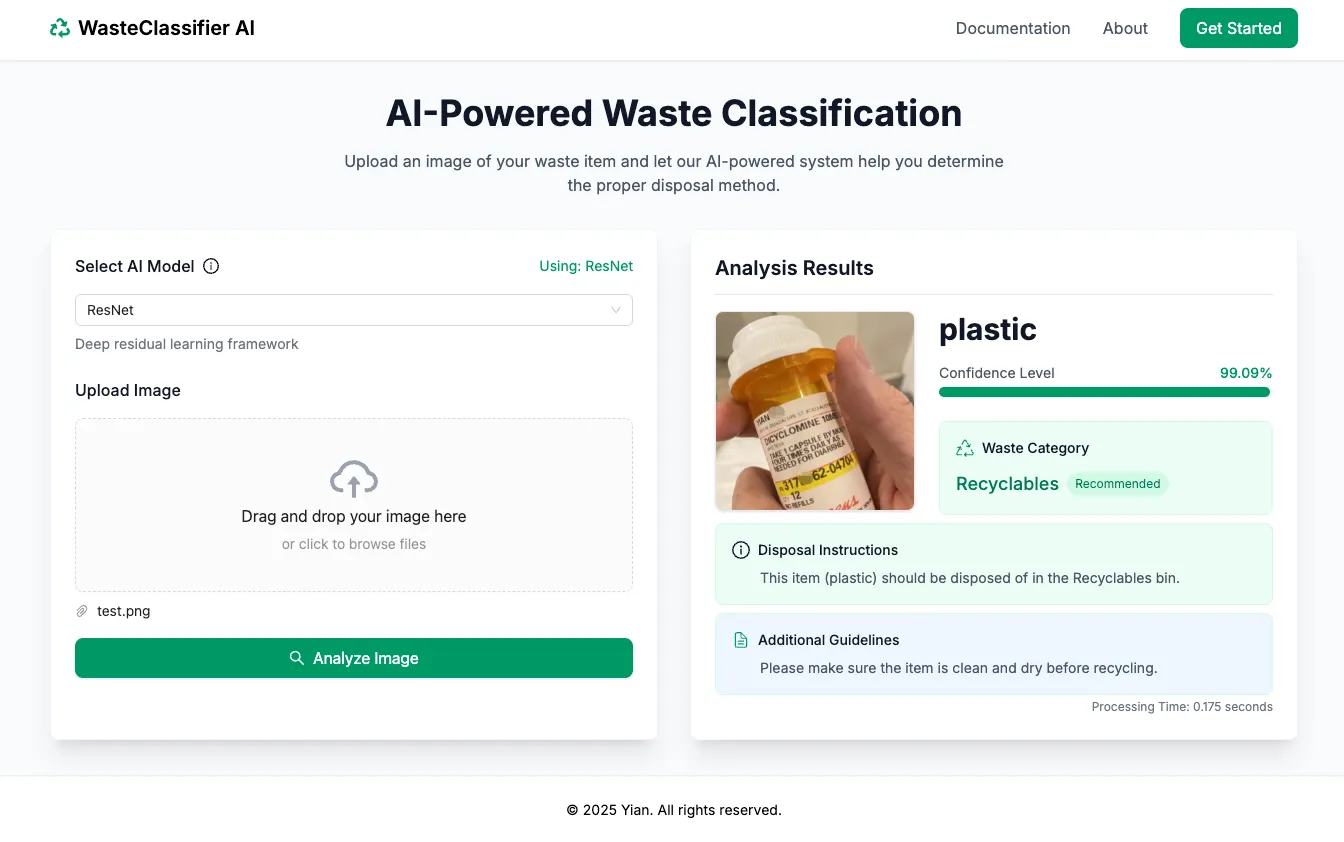
SmartBin is an AI-powered waste classification system. You upload a photo of any piece of trash and a deep learning model decides which category it belongs to — recycle, compost, landfill, hazardous — fast enough to feel like a tool, not a demo. The backend is a FastAPI service that hot-swaps between eleven pretrained image classification models so you can compare accuracy, latency, and memory footprint side by side.
The models are trained separately in a sibling repo, GarbageClassfication, which owns the dataset pipeline, training scripts, and evaluation tools. SmartBin itself is the inference + serving layer.
Supported models
A single dropdown swaps between these, each loaded on demand:
- DenseNet (
densenet201) - EfficientNet (
efficientnet_b7) - GoogLeNet
- LeNet
- MobileNetV2 / MobileNetV3 (
mobilenet_v2/mobilenet_v3_large) - ResNet (
resnet50) - AlexNet
- ShuffleNetV2 (
shufflenet_v2_x2_0) - VGG
- RegNet (
regnet_x_32gf)
Each model runs on whatever hardware is available — CUDA first, then MPS on Apple Silicon, CPU as a fallback — with no configuration.
Stack
- Backend — FastAPI with an
/api/predictendpoint that accepts an image upload and a model name, returns the top-k predictions with softmax probabilities. - Model loading — PyTorch modules loaded lazily from a
weights/directory. Weights are hosted on Google Drive (too large for git) and fetched once at deploy time. - Frontend — Next.js + TypeScript, drag-and-drop upload with live prediction feedback and a model picker for comparison runs.
- Deployment — Dockerized for portability, AWS-hosted at smrtbin.com.
Notable bits
- Eleven models, one endpoint — the picker turns SmartBin into an impromptu benchmarking tool. Point the same bottle at each model and watch which ones disagree.
- Hot-swappable weights — models load lazily, so the container boots fast and only pays the memory cost for whichever model is actually in use.
- Hardware-adaptive — same code path on CPU, CUDA, and MPS
thanks to PyTorch’s
torch.deviceauto-detection.