 ★
★
EchoVessel
Local-first digital persona engine with long-term memory, voice, and channel integrations — carry an echo long enough for it to become presence.
- Type
- CLI
- Role
- Solo
- Status
- Active
- Tech
- Python 3.11+ FastAPI SQLite + sqlite-vec React 19 Vite TypeScript sentence-transformers FishAudio TTS Whisper discord.py pytest
- Started
- Apr 2026
EchoVessel is an open-source digital persona engine. You define or distill a persona from your own settings and source material, then run it as a long-lived companion that remembers, speaks, and grows with you — instead of resetting after every reply.
The core idea: a persona shouldn’t feel like a new tab every time you open it. It should feel continuous.
Why this exists
Most chat tools treat memory as a vector dump and identity as a system prompt. The result is responsive, but never present. EchoVessel asks a different question: what does it take for a digital persona to feel like the same person tomorrow as it was today? The answer turned out to be a system, not a feature — one where memory, voice, and behavior all serve the same continuity.
What it actually does
Five modules cooperating inside a single local daemon:
- memory — long-term persona memory, hierarchical (L1–L6)
- voice — text-to-speech, speech-to-text, voice cloning
- proactive — autonomous outreach with policy gates
- channels — pluggable transports (Web, Discord, more on the way)
- runtime — the daemon that ties everything together
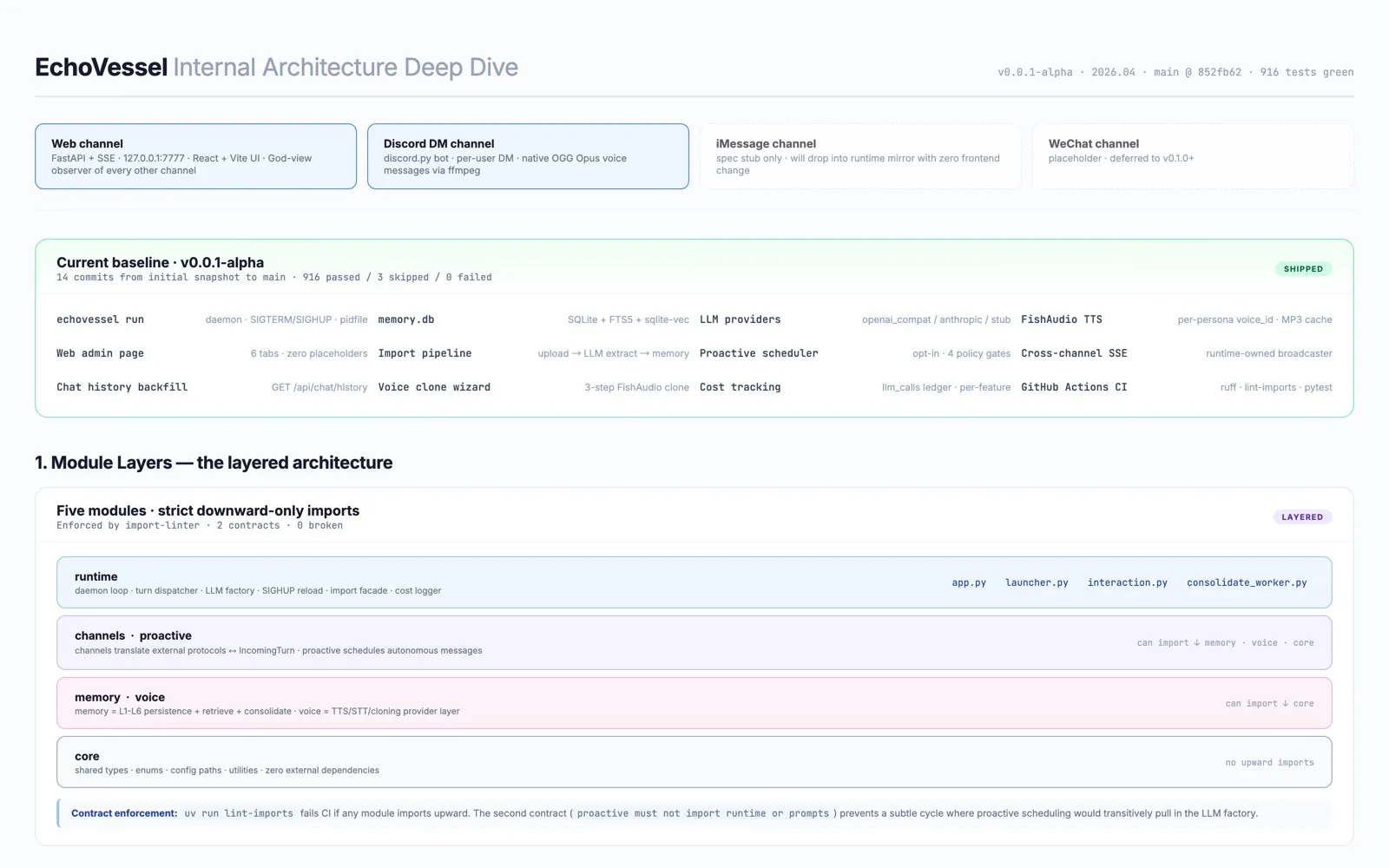
Open the full architecture diagram →
Memory is the heart of it
Most “AI memory” is a search problem: find the most similar past chunk, paste it into the prompt. EchoVessel treats memory as a structure — six layers, each answering a different question about the persona’s relationship with you.
| Layer | Question it answers | What it stores | Written when | Role at read time |
|---|---|---|---|---|
| L1 · core blocks | ”Who am I right now?” | Short, stable text — persona, self, user, relationship, style | Manually, on admin edits, or via import | Always injected into the prompt, unconditionally |
| L2 · recall messages | ”What was literally said?” | Every user and persona message, verbatim, FTS5-indexed | On every turn, immediately | Ground-truth archive; expands context around L3 hits |
| L3 · events | ”What happened in that conversation?” | One-line episodic facts with emotional impact, tags, embedding, and an optional day-precision event_time window | When a session closes (extraction pass) | Primary target of vector retrieval; day-precision delta renders as “a few days ago” / “next week” in the prompt |
| L4 · thoughts, intentions, expectations | ”What do I believe about this person, what have I promised, what am I expecting?” | Backward-looking insights, strict persona-side commitments, and forward-looking expectations with due dates — all in the same table, distinguished by type | Reflection (fast loop) + a slow-tick phase that runs between sessions | Vector-retrieved; pinned persona-thoughts also render as # About {speaker}, promises as # Promises you've made, expectations as # You've been expecting |
| L5 · entities + aliases | ”Who are the third parties I know about, and what do they go by?” | Canonical names, any aliases (“Scott” = “黄逸扬”), and a many-to-many junction to the events they appear in | Extraction at session close, with a three-tier dedup (alias match → embedding thresholds → ask-user when uncertain) | Alias scan on every query; an exact alias hit pulls every linked event into the candidate pool with a rerank bonus — the engineering basis for cross-language recall |
| L6 · episodic state | ”How do I feel right now?” | A single-row JSON snapshot: mood, energy, last user signal, timestamp | As a side effect of extraction — no extra LLM call | Renders as # How you feel right now in the system prompt; decays back to neutral after 12 hours so a long quiet period doesn’t open under stale affect |
How a memory gets picked
When the persona is about to reply, every candidate gets ranked by a five-factor score:
score = 0.5 · recency + 3.0 · relevance + 2.0 · impact + 1.0 · relational_bonus + 1.5 · entity_anchor- recency — exponential decay with a 14-day half-life
- relevance — vector similarity to the current query, normalized to
[0, 1] - impact —
|emotional_impact| / 10, so peak moments outweigh forgettable ones on ties - relational_bonus — a flat
+1.0whenever a memory carries an identity-bearing, vulnerability, turning-point, commitment, or correction tag - entity_anchor —
+1.0whenever the query mentioned an alias that resolves to this memory’s linked entity; the escape hatch for cross-language recall where the embedder sees zero overlap
A min_relevance floor (default 0.4) drops orthogonal matches
before scoring, so a high-impact unrelated event cannot sneak in
on the back of the impact weight. Entity-anchored candidates bypass
the floor — if you asked about “Scott” and the event only mentions
“黄逸扬”, the anchor is allowed to carry it through. The shape of
this formula owes a debt to the Stanford “Generative Agents”
paper; the relational and entity-anchor bonuses are the parts
tailored to persona memory.
The hard problem isn’t storage. It’s deciding what to remember, how to represent it, and when it should wake up and influence the next reply.
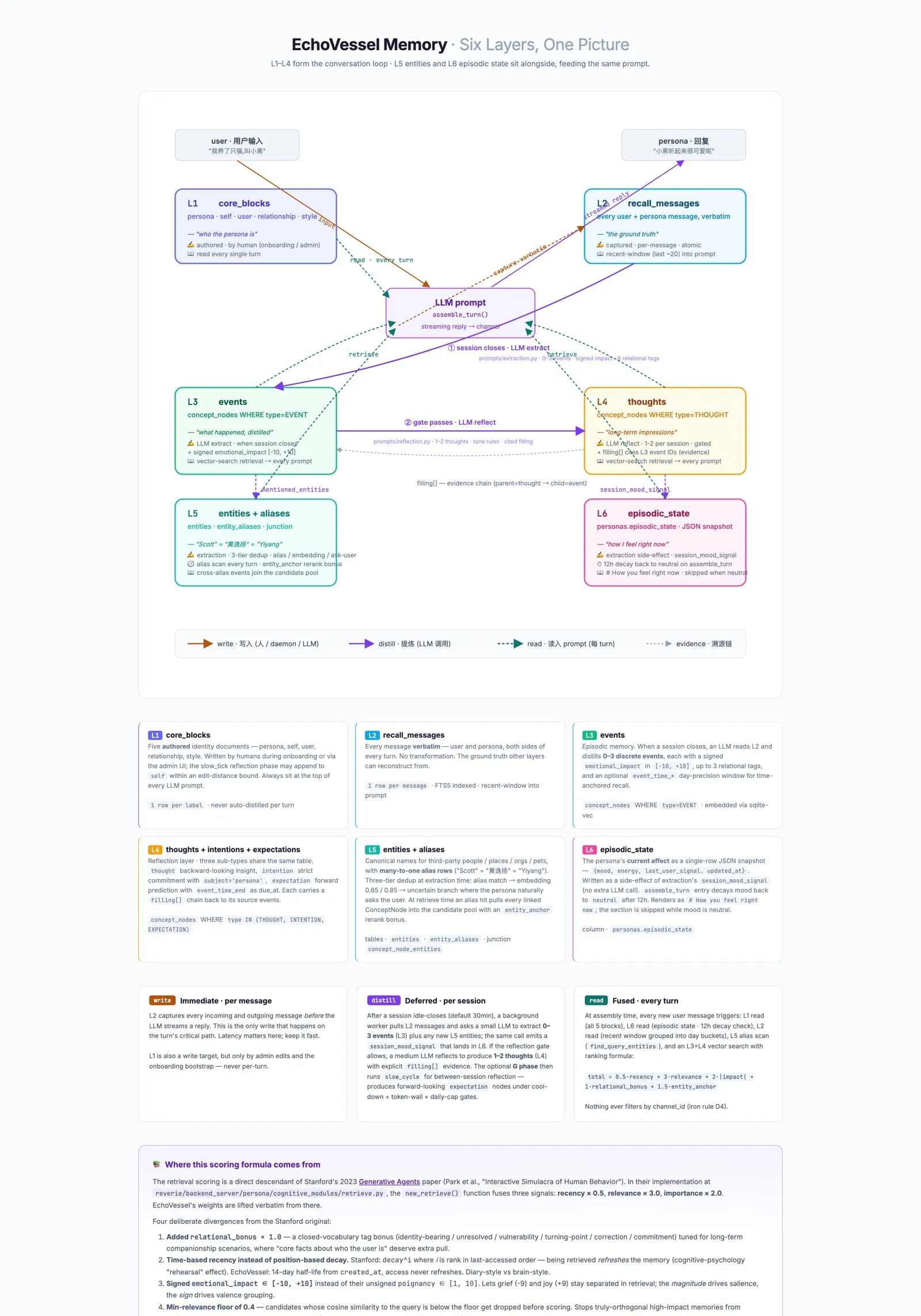
Open the interactive memory diagram →
How a single message wakes the system up
Every message triggers a small choreography across layers: which memories surface, which get written, which get distilled into longer-term form. The companion runtime-flow page traces this turn-by-turn against a real conversation.
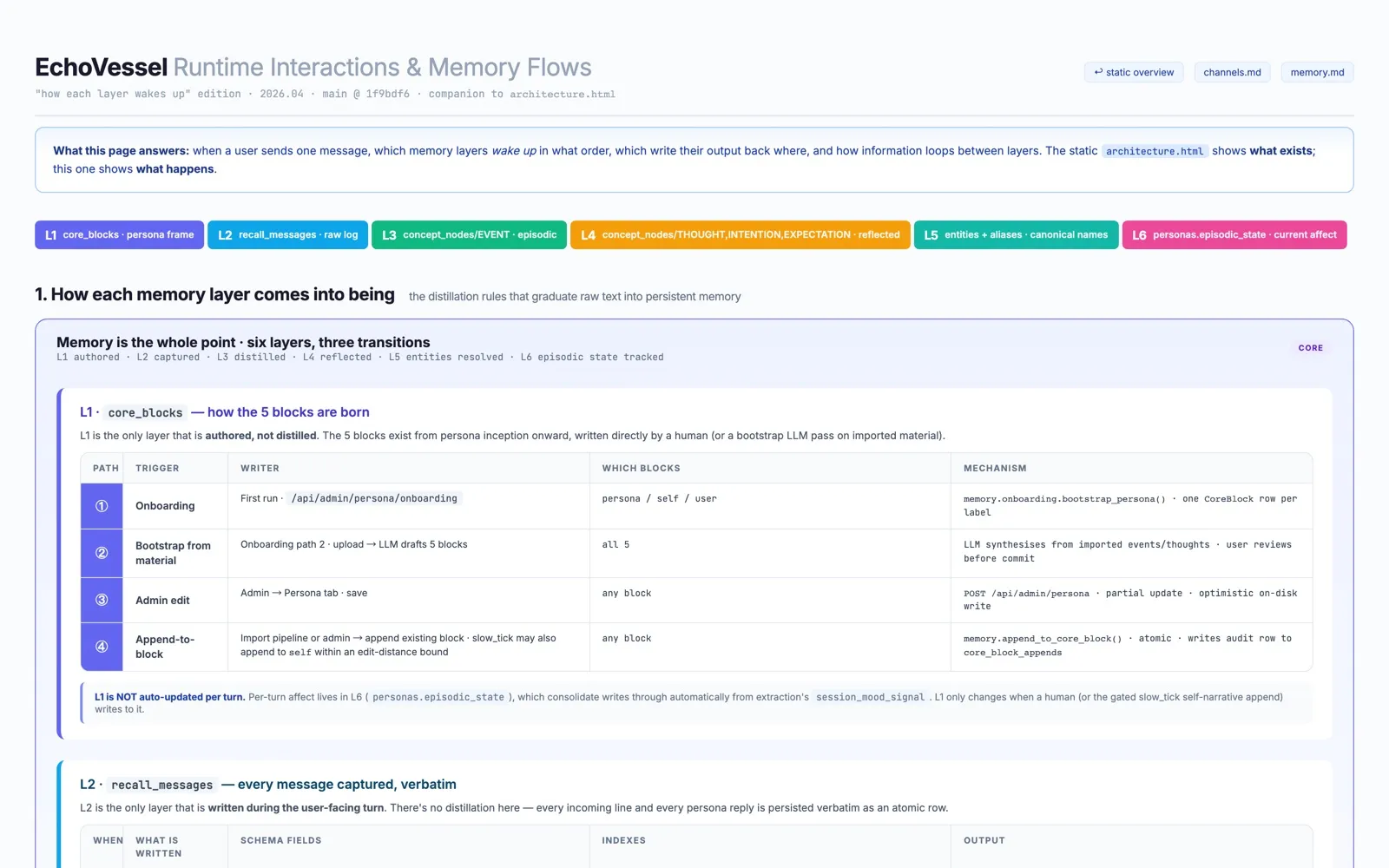
Open the runtime flow diagram →
Thinking between turns
A persona that only ever reacts when you speak is a chatbot. A companion should also think about you when you’re quiet.
Between sessions, a small reflection phase runs as part of the consolidate worker. It reads recent events and produces forward- looking output as typed memory nodes — observations that became visible, commitments the persona has made to itself, and expectations about what you might bring up next. When you come back and say “anything on your mind?”, the reply can reference specific content the persona was turning over — not freshly generated flattery, but something that actually got written down while you were away.
The phase is fenced in carefully. There are token walls per cycle, a daily cap, a kill switch in config, a 20% edit-distance bound on self-narrative appends, and a closed enumeration of what kinds of nodes the reflection can write. It is not allowed to invent new goals, schedule future actions, call external APIs, or recurse. The design constraint is honest reflection with strict blast radius.
Voice as identity
Voice isn’t a TTS afterthought. Each persona has its own voice (cloned or selected) that speaks across every channel — including native Discord voice messages, indistinguishable from the bubble a human friend would send.
Relationships without affection meters
EchoVessel doesn’t have a “likeability score.” A persona’s bond with you is visible in behavior — tone shifts, naming changes, deeper recall, more initiative — not a progress bar.
Local-first by default
Your persona lives on your machine. The data file sits in
~/.echovessel/memory.db. The embedder runs locally. The only
network traffic is to the LLM endpoint you configure. No
telemetry, no phone-home, no gradual creep into the cloud.
Ethics & open source
EchoVessel is for fictional characters, original characters, your own self-persona, consented digital counterparts, and creative or memorial reconstructions. It is not an impersonation tool for pretending to be a real person in external communication.
It stays open-source because digital presence and intimate computing tools should not belong only to closed commercial platforms.
Name
EchoVessel — carry an echo long enough for it to become presence.