 ★
★
EchoVessel
本地优先的数字人格引擎,具备长期记忆、语音与多渠道接入——让回声长久留存,直到成为陪伴。
- 类型
- 命令行
- 角色
- 独立开发
- Status
- 进行中
- Tech
- Python 3.11+ FastAPI SQLite + sqlite-vec React 19 Vite TypeScript sentence-transformers FishAudio TTS Whisper discord.py pytest
- Started
- 2026年4月
EchoVessel 是一个开源的数字人格引擎。你用结构化设定和素材定义、或从一段已有材料里蒸馏出一个人格,然后让它作为一个会记住你、会说话、会随时间生长的长程伙伴运行——而不是每次回复后就重置。
核心理念:一个人格不该像每次打开都是空白的新标签页,它应当是连续存在的。
为什么做这个
大多数对话工具把记忆当成向量堆,把身份当成 system prompt。结果是反应灵敏,但从不真正”在场”。EchoVessel 想问的是另一个问题:要让一个数字人格今天和明天感觉是同一个”人”,到底需要什么?答案是一套系统,而不是一个功能——记忆、语音、行为都为同一种连续性服务。
它实际在做什么
五个模块在一个本地守护进程里协作:
- memory —— 长期人格记忆,分层(L1–L6)
- voice —— 语音合成、语音识别、声音克隆
- proactive —— 带策略门控的自主主动消息
- channels —— 可插拔的对话渠道(Web、Discord,更多正在路上)
- runtime —— 把上面这些串起来的守护进程
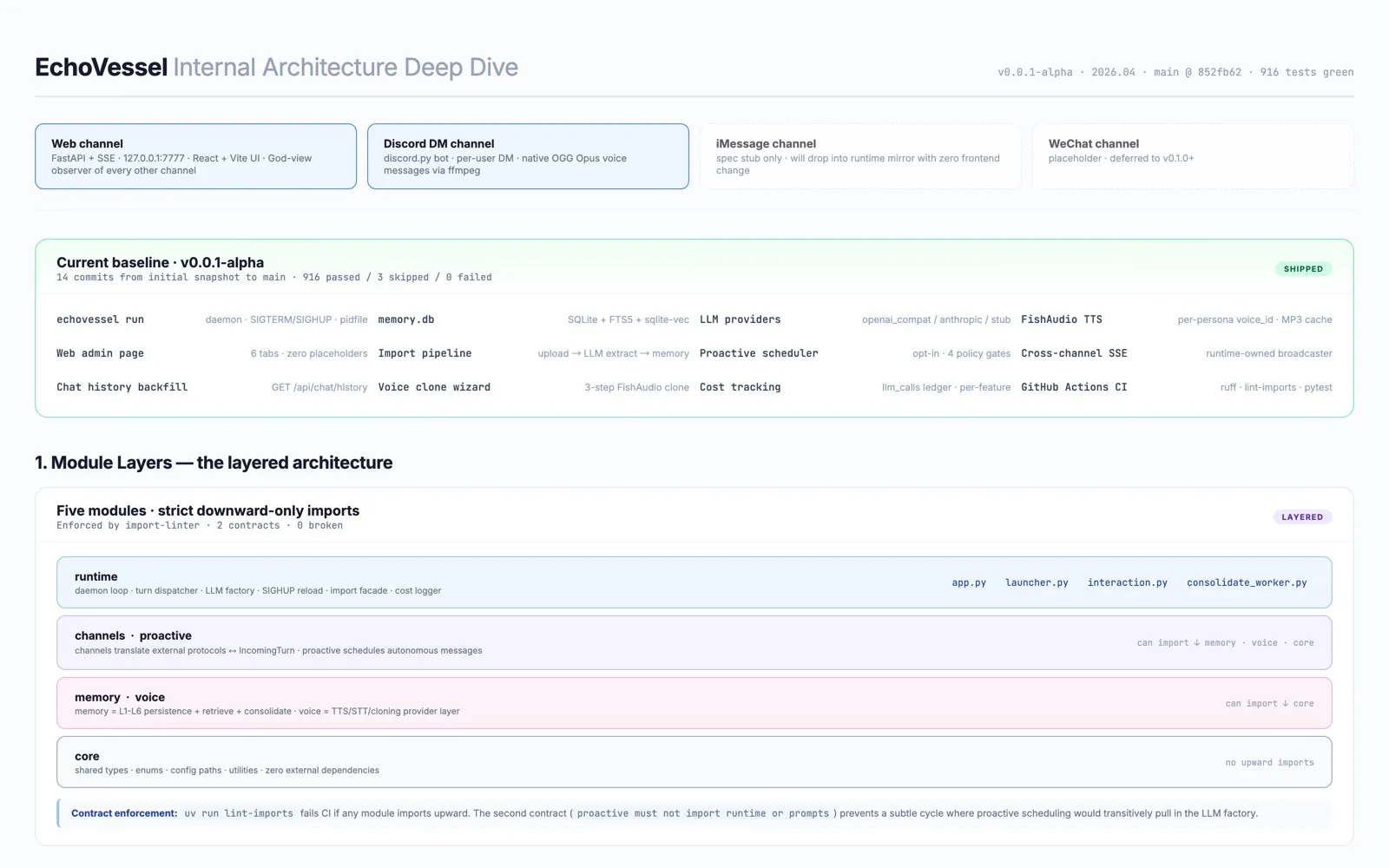
记忆是它的心脏
大多数所谓的”AI 记忆”本质上是个搜索问题:找出最相似的历史片段,塞进 prompt。EchoVessel 把记忆当作结构来处理——六层,每一层回答关于”人格与你之间关系”的不同问题。
| 层 | 它回答的问题 | 存什么 | 何时写入 | 读取时的角色 |
|---|---|---|---|---|
| L1 · 核心块 | ”我现在是谁?“ | 简短稳定的文本——persona、self、user、relationship、style | 手动设定、admin 编辑、import 导入时 | 无条件注入每一次 prompt |
| L2 · 原始对话 | ”刚才到底说了什么?“ | 用户和人格的每一条消息,逐字记录,带 FTS5 索引 | 每一回合实时写入 | 原始档案;在 L3 命中后扩展上下文 |
| L3 · 事件 | ”这段对话里发生了什么?“ | 一行的情节事实,带情绪强度、标签、向量 embedding,以及可选的 day 精度 event_time 窗口 | 会话关闭时(extraction 抽取阶段) | 向量检索的主要目标;day 精度 delta 在 prompt 中渲染成”几天前” / “下周”这样的时间锚 |
| L4 · 反思、承诺、期待 | ”跨越多次对话我对这个人形成了什么看法?我许下了什么承诺?我在期待什么?“ | 回望型的 thought、严格以人格为主语的 intention、以及带 due date 的 forward-looking expectation —— 同一张表,靠 type 区分 | fast-loop reflection + 会话之间跑的 slow-tick 阶段 | 向量检索;被 pin 的 persona-thought 渲染成 # About {speaker} ,承诺渲染成 # Promises you've made,期待渲染成 # You've been expecting |
| L5 · entities + aliases | ”我认识的第三方人物叫什么?又有哪些别名?“ | canonical name、任意数量的 alias(“Scott” = “黄逸扬”)、以及到他们出现过的事件的多对多 junction | extraction 阶段,走三层 dedup(精确 alias → embedding 阈值 → 不确定就让人格自然问 user) | 每次 query 都跑一次 alias 精确匹配;命中会把该 entity 关联的所有事件拉进候选池并加分——跨语种召回的工程基础 |
| L6 · episodic state | ”我此刻心情如何?“ | 一行 JSON snapshot:mood、energy、last user signal、时间戳 | extraction 的副作用——不额外调 LLM | 在 system prompt 里渲染成 # How you feel right now;12 小时没更新会 decay 回 neutral,避免长时间沉默之后用陈旧情绪打开下一轮 |
一段记忆是怎么被挑出来的
人格准备回复前,每一个候选都会被一个五因子的分数排序:
score = 0.5 · recency + 3.0 · relevance + 2.0 · impact + 1.0 · relational_bonus + 1.5 · entity_anchor- recency —— 指数衰减,半衰期 14 天
- relevance —— 当前 query 的向量相似度,归一化到
[0, 1] - impact ——
|emotional_impact| / 10,让高强度时刻在打平时胜出 - relational_bonus —— 当记忆带 identity-bearing、vulnerability、turning-point、commitment、correction 等标签时,加
+1.0 - entity_anchor —— query 里出现了某个 alias、而这条记忆恰好关联到该 entity 时,加
+1.0;这是 embedder 完全看不出语义重叠时的兜底通道
min_relevance 阈值(默认 0.4)在打分之前把完全不相关的候选过滤掉——这样一个高强度但跟当前话题无关的事件,就不能靠 impact 项偷偷蹭进来。entity-anchor 命中的候选绕过这道闸:你问的是 “Scott”、而事件里只写了 “黄逸扬”,anchor 有权让它通过。这个公式的骨架来自 Stanford “Generative Agents” 论文;relational 和 entity-anchor 两项是为人格记忆量身加的。
难的不是存储。难的是决定什么该被记住、怎样被表示、什么时候该被唤醒来影响下一句回复。
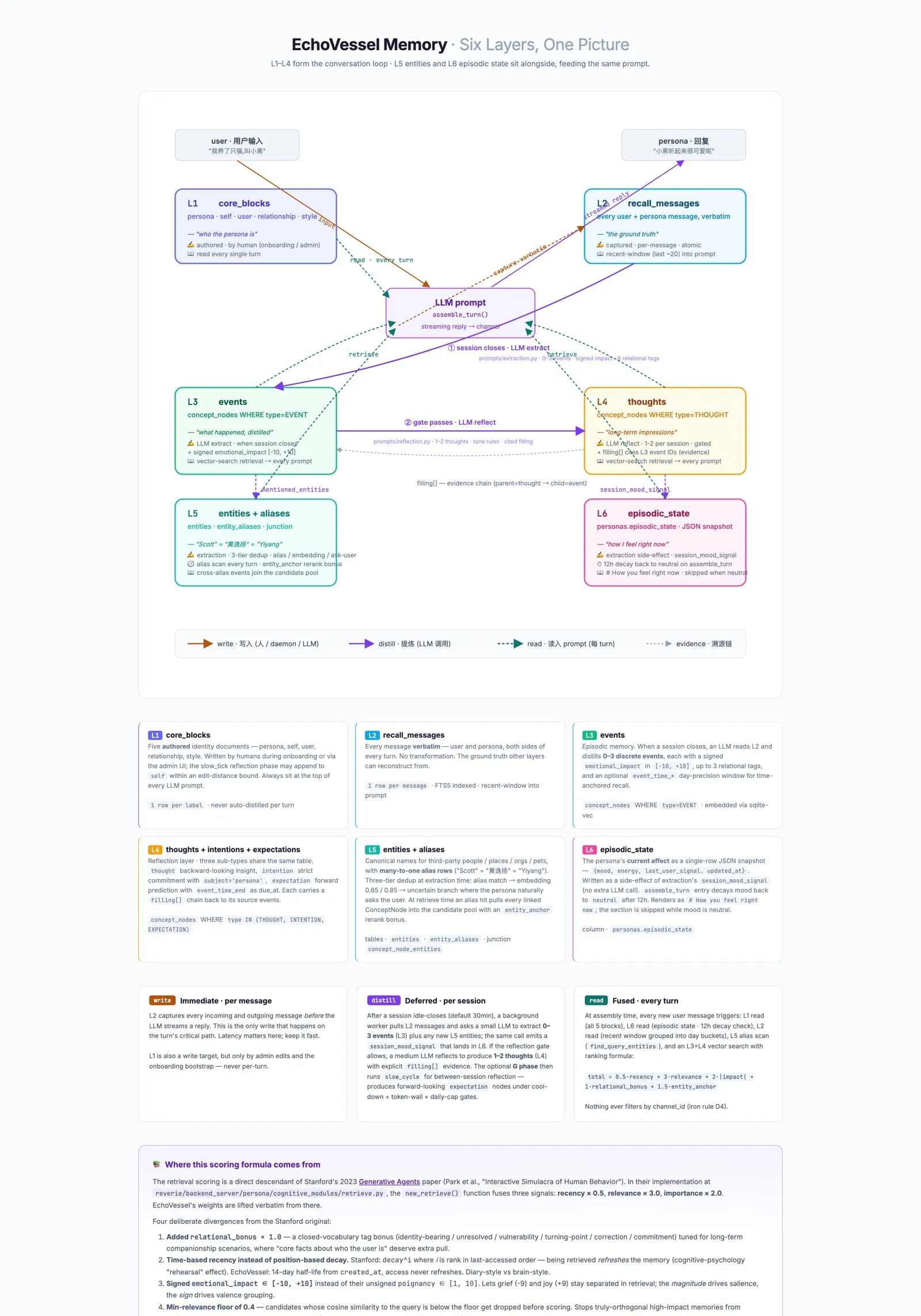
一条消息如何唤醒整个系统
每一条消息都会触发各层之间的一段小型编排:哪些记忆浮上来、哪些被写下、哪些被进一步蒸馏成更长程的形式。这张运行时流程图把这套过程逐 turn 对着一段真实对话拆开。
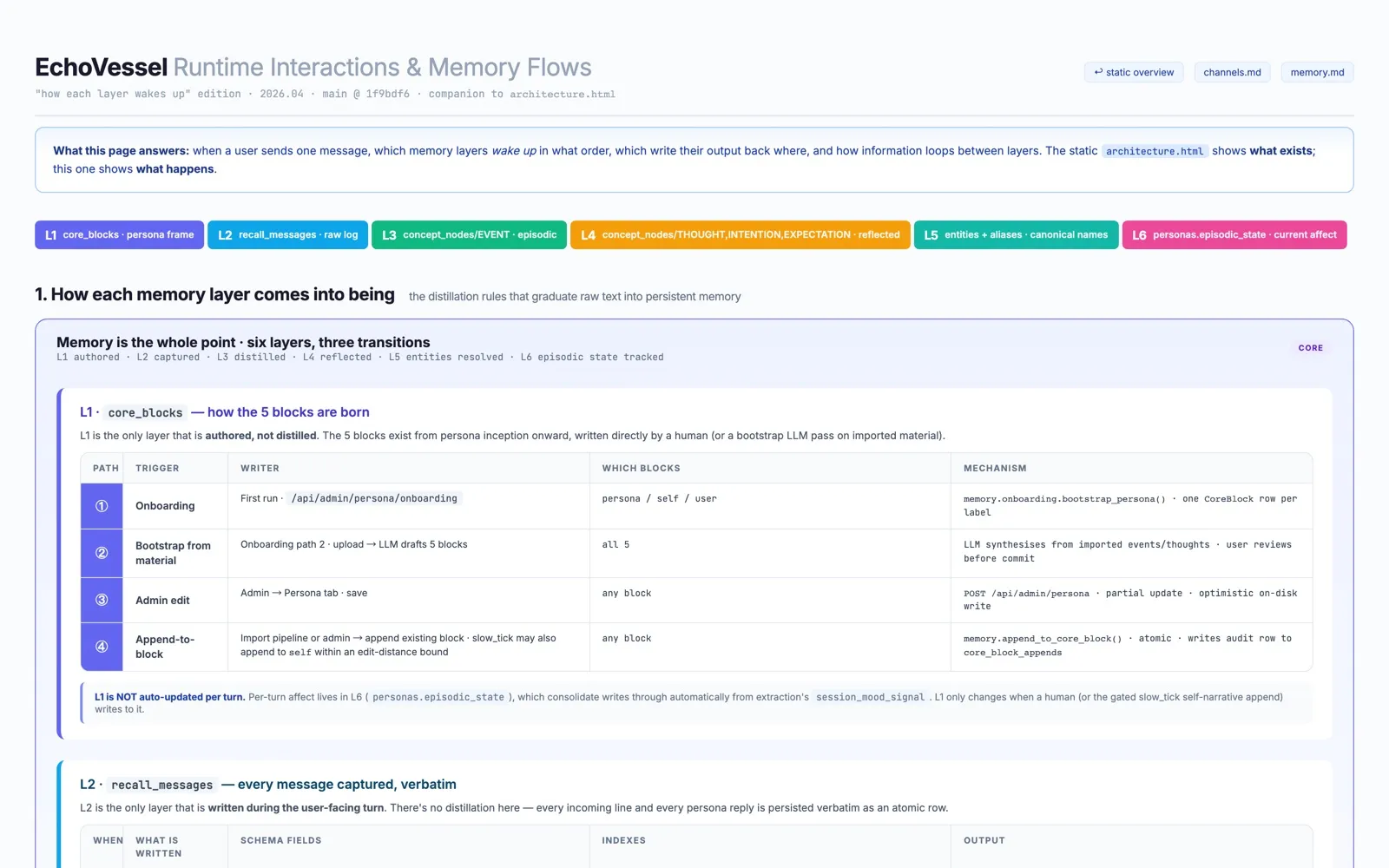
在你不说话的时候也想你
一个只会对你的话做出反应的人格,本质上还是 chatbot。一个真正陪伴你的人格,在你沉默的时候也应该在想你。
在两段会话之间,consolidate worker 末尾会追加一段小型的反思阶段。它读取最近的事件,产出 forward-looking 的输出——成为 thought 的观察、人格对自己立下的承诺、以及对”你接下来可能会说起什么”的期待——全部以类型化的记忆节点形式落库。等你再回来问一句”最近在想什么”,回答里可以引用你不在时它真正写下的东西,而不是当场编出来的寒暄。
这条链路被封得很严。每个 cycle 有 token wall、每天有 cap、config 里有 kill switch、自我叙事的 append 被 20% edit distance 约束住,能写的节点类型是一份封闭枚举。它不被允许创造新目标、schedule 未来动作、调外部 API、或递归触发自己。设计约束是:诚实的反思 + 严格受控的辐射半径。
声音即身份
语音不是 TTS 的事后补丁。每个人格都有自己的声音(克隆或挑选),跨所有渠道说话——包括 Discord 上的原生语音消息,气泡和真人发出的完全一样。
没有好感度条的关系
EchoVessel 没有”好感度数值”。一个人格与你之间的羁绊,体现在行为里——语气的变化、称呼的更替、更深的回忆、更多的主动——而不是一根进度条。
默认本地优先
你的人格活在你自己的机器上。数据存在 ~/.echovessel/memory.db。Embedder 在本地跑。唯一的对外流量是发往你自己配置的 LLM 端点。无遥测、无回传、不会慢慢往云上漂。
伦理与开源
EchoVessel 适用于虚构角色、原创角色、自我人格、授权同意的数字分身,以及纪念性 / 创作性 / 研究性的重建。它不是一个用来在对外沟通中冒充真实他人的工具。
它保持开源,是因为数字存在与亲密计算工具不应只属于封闭的商业平台。
名字的含义
EchoVessel —— 把回声承载得足够久,久到成为陪伴。